- Deep Voice 파트 1 링크
- 이 글은 저자(Dhruv Parthasarathy)의 허락을 받아 번역하여 게시하는 글입니다.
- 원문은 https://blog.athelas.com/baidu-deep-voice-explained-part-2-training-810e87d20047에서 확인할 수 있습니다.
- 원작자를 ‘나‘로 표기하였습니다, ‘최근‘이라는 단어는 2017년 3년을 기준이므로 지금(2019년)과의 차이가 있을 수 있음을 미리 밝힙니다.

Arxiv 링크: https://arxiv.org/abs/1702.07825
기관: Baidu Research
Baidu의 TTS 시스템에 딥러닝을 적용시켰던 Deep Voice에 대한 두번째 포스팅이다.
이 포스팅에서 우리는, 레이블링한 데이터를 이용하여 전체 파이프라인의 각각의 부분들에 어떻게 학습을 시키는지를 다룰 것 이다.
배경 지식
- Adam Coates’ lecture (3:49부터 볼 것)
- 이전 포스팅 (파이프라인에 대한 이해)
- Stephen Merity 의 블로그 포스팅: Google’s Neural Machine Translation architecture.
- Deep Voice 팀의 포스팅
TTS의 추론(inference) 파이프라인에 대한 요약
파이프라인에 대한 포스팅을 확인할 것
[번역] Baidu Deep Voice: Part 1 – Text-to-speech 파이프라인(The Inference Pipeline)
간단히 요약하면 아래와 같다.
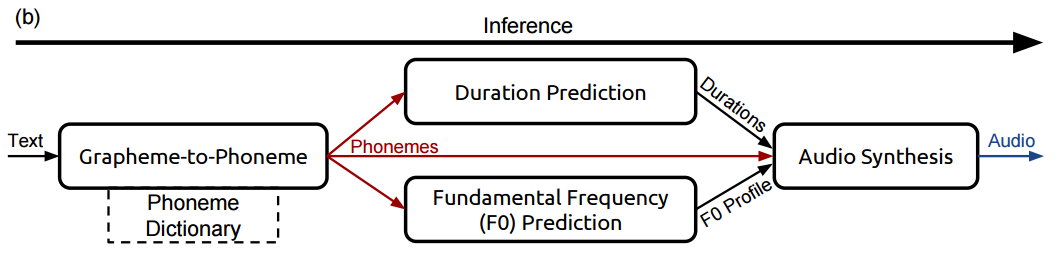
1. 텍스트를 음소로 바꾸기: Grapheme-to-Phoneme
- “It was early spring” -> [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
2. 각 음소에 길이와 주파수 정보를 담는 것
- [IH1 (140hz, 0.1s), T (142hz, 0.05s), . (Not voiced, 0.01s), … ]
3. 음소와 길이, 주파수를 합쳐 텍스트를 표현하는 음성을 만들어내는 것
- [IH1 (140hz, 0.1s), T (142hz, 0.05s), . (Not voiced, 0.01s), … ] -> Audio
그러나 어떻게 신뢰할만한(reliable) 음성합성을 위해, 우리는 실제로 어떠한 방식을 통해 학습을 시킬 수 있을까?
학습 파이프라인 – Deep Voice 트레이닝을 위한 데이터 사용
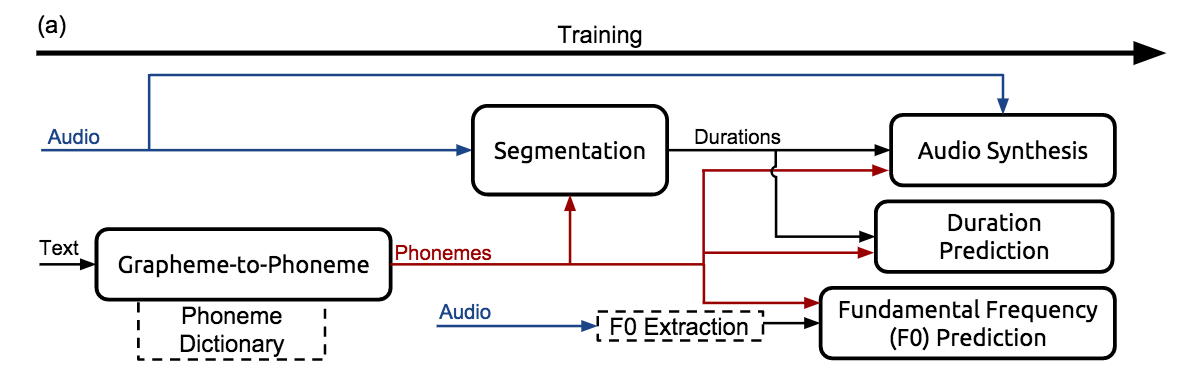
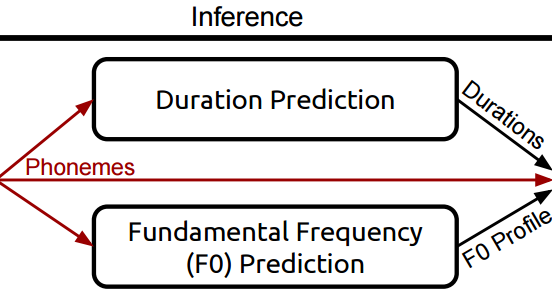
Deep Voice는 추론(inference)과정동안 위의 그림과 같은 파이프라인을 통해 학습을 한다.
이 파이프라인 각각의 부분들을 살펴보고, 그 부분들이 전체의 시스템 학습에 어떻게 도움을 주는지 알아보자. 아래에 우리가 사용할 데이터는 다음과 같다. 바로, 주어진 대본를 발화한 녹음 (음성) 과 그에 해당하는 텍스트 이다.
첫번째 단계: Graphene-to-Phoneme 모델 (텍스트를 음소로)
Inference과정의 첫번째 단계는 Graphene-to-Phoneme 모델을 이용하여 텍스트를 음소로 바꾸는 것이 었다. 이전 포스팅의 예를 떠올려보자
- 입력: “It was early spring”
- 출력: [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
대부분의 경우, 이 시스템을 통해 텍스트를 음소 사전(예: CMU) 으로 전달하고 출력값을 받을 수 있게 구성한다.
그러나 만약 이전에 본 적이 없는 새로운 단어가 있는 경우에는 어떻게 할까? 이런 일은 실제 사전에 단어가 추가되는 현상과 동일하다 (‘google’, ‘screencast’ 등과 같은 신조어들). 분명하게도, 우리는 새로운 단어를 만났을 때 그 음소들을 예측할 수 있는 대체 시스템이 필요하다.
Deep Voice는 신경망을 이용하여 이 작업을 달성한다. 실질적으로는 Sequence to Sequence (Seq2Seq) 를 통해 텍스트의 음소를 예측하는 Microsoft Research 팀의 Yao 와 Zweig의 작업을 활용한다.
이 모델들을 세부적으로 설명하기보다는, 이를 설명하는 제일 좋은 자료를 하나 첨부한다.
- 위의 유튜브 영상은 Bay Area Deep Learning School에서 Quoc Le의 Seq2Seq 학습에 대한 프리젠테이션이다. 그는 Google Brain의 Deep learning 연구자이고, Seq2Seq 모델의 저자이다.
- Deep Learning Book (Goodfellow 등이 저술) Recurrent Neural Networks 와 LSTM 챕터
데이터의 형태
그렇다면 학습용 데이터와 그에 해당하는 레이블은 실제로 어떻게 생겼을까?
입력값 (X – 단어와 단어들)
- [“It”, “was”, “early”, “spring”]
레이블 (Y)
- [[IH1, T, .], [W, AA1, Z, .], [ER1, L, IY0, .], [S, P, R, IH1, NG, .]]
입력값과 해당하는 레이블의 쌍은 CMU에서 제공한 것과 같은 표준 음소 사전으로 부터 얻을 수 있다.
두번째 단계: 분절(segmentation) 모델 실행
앞선 포스팅을 보았다면 이했듯이, inference 과정 동안 우리는 음소의 길이와 기본주파수(F0; underlying tone)을 알아야 한다. 우리는 이 길이와 기본주파수 값을 음소의 클립으로 부터 얻을 수 있다.
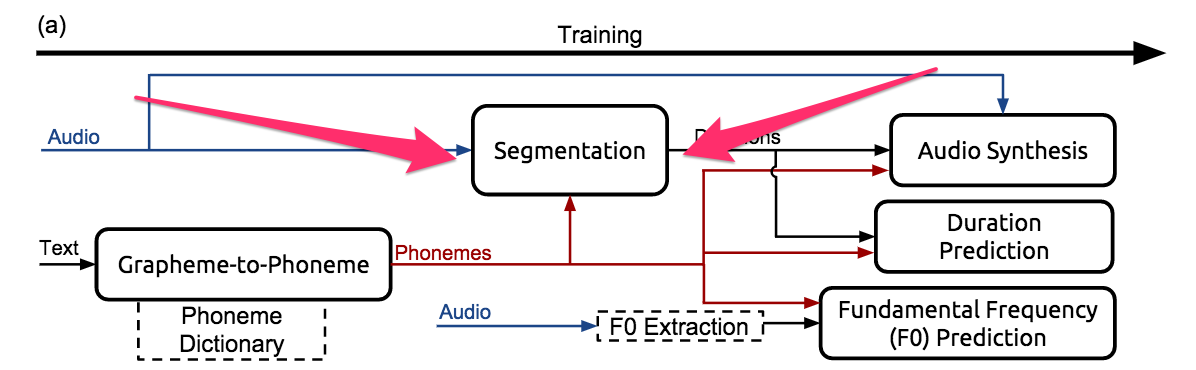
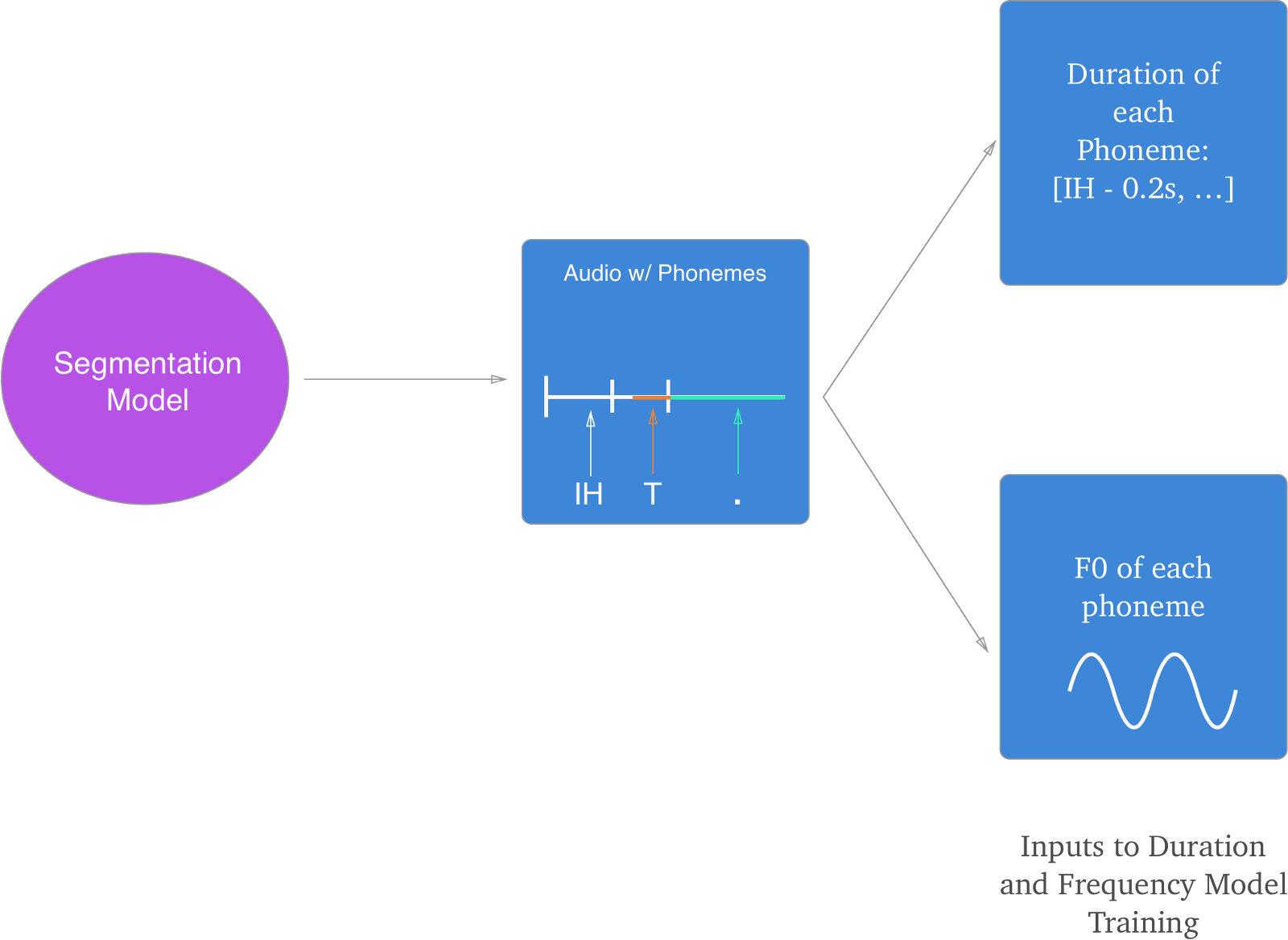
Deep Voice는 Segmentation 모델이라고 부르는 것을 이용하여 각 음소의 audio clip을 얻는다.
Segmentation 모델은 각 음소과, 그것이 발성된 음성파일의 특정 세그먼트(분절)를 맞춘다. 아래의 그림과 같이 입력과 출력에 대한 개요를 간략하게 이해해볼 수 있다.
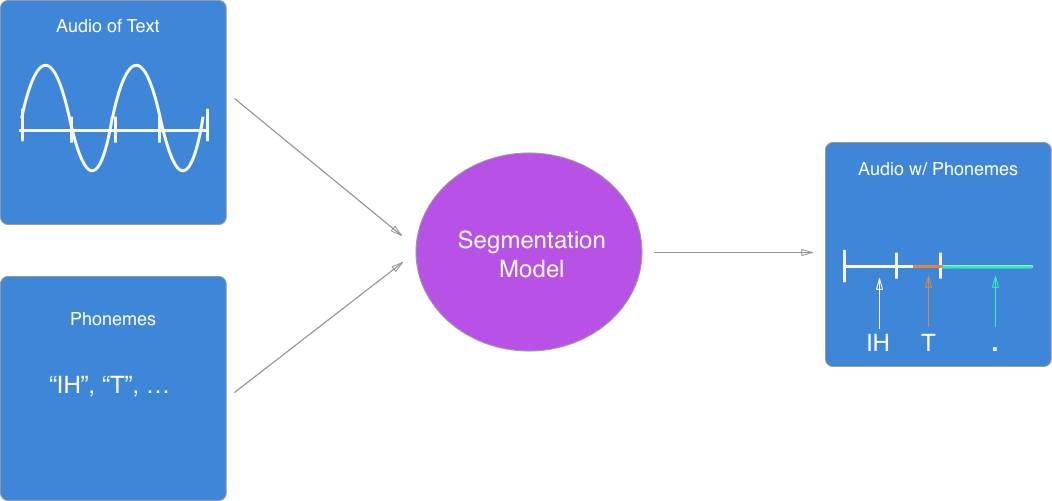
데이터의 형태
Segmentation model의 구현에 있어서 특히나 흥미로운 점은, 각각의 음소의 위치를 예측하는 것 대신 이 모델은 ‘한쌍의 음소(a pair of phonemes)’의 위치를 예측한다.덧붙여 이 모델은 음소의 위치를 적은 실제의 레이블(ground-truth label)이 없는 상태에서 비지도적(unsupervised) 학습을 한다. CTC loss 값을 기반으로 학습을 진행하는데, 이곳을 참고해라.
역자주: CTC는 Connectionist Temporal Classification 의 약자로, 논문을 보니 각각의 음소에 대한 labeling 없이도 unsupervised learning을 통해 labeling을 예측하는 알고리즘을 말하는 듯 합니다.
이 모델을 위한 데이터는 다음과 같다.
입력(X)
- 음성 클립 “It was early spring”
- 음소들 [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
출력(Y)
- 쌍으로 이루어진 음소 및 그 시작 시간 [(IH1, T, 0:00), (T, ., 0:01), (., W, 0:02), (W, AA1, 0:025), (NG, ., 0:035)]
왜 개별 음소가 아닌 한쌍의 음소의 위치를 예측하는가? 우리는 음소 및 그 에 해당하는 시간 구간(timestamp)을 확률적으로 구하게 되는데, 그 구간의 중앙지점이 사실상 가장 그 음소가 위치할 확률이 높다는 이야기가 된다.
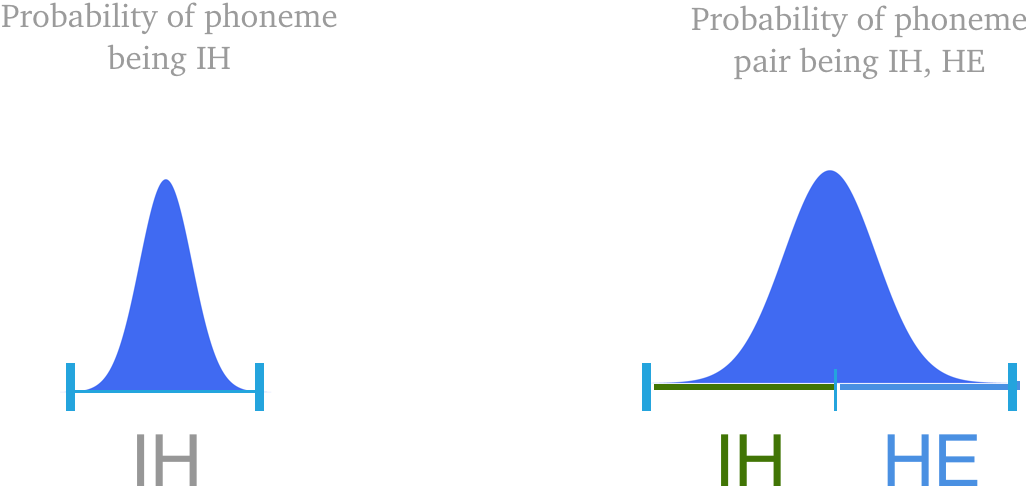
그러나 음소를 쌍으로 둘 경우, 가장 높은 확률은 두 음소의 경계 구간에서 이루어진다 (위의 그림). 따라서, 음소를 쌍으로 이용하는 것은 두 음소의 경계를 쉽게 찾는데 큰 도움을 준다.
이 과정의 마지막으로부터, 우리는 각 음소가 오디오 클립의 어느 위치에 있는지 명확한 아이디어를 얻을 수 있다.
세번째 단계: 길이(duration)와 기본주파수(fundamental frequency) 예측
두번째 단계의 Segmentation 모델로 부터 길이와 기본주파수를 얻었기에, 이 값들을 이용하여 새로운 음소에 대한 두 값들을 예측하는 모델을 학습시킬 수 있다.
Deep Voice는 두 값을 한번에 출력해내는, 각각의 두 요소를 합친 단일 모델을 사용한다.
데이터의 형태
입력(X)
- 음소들 [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
레이블(Y)
- 각 음소의 길이와 F0값. 이는 segmentation model로 부터 얻어진다. [(IH, 0.05s, 140 hz), (T, 0.07s, 141 hz), … ]
이로서 길이와 F0 값을 예측해낼 수 있게되었다.
네번째 단계, 음성 합성 트레이닝
파이프라인에서 마지막으로 우리는 실제로 사람이 소리내는 음성을 생성하는 단계를 학습시켜야 한다. DeepMind의 WaveNet 처럼, 이 모델은 다음과 같은 구조를 따른다.

아래에 입력값과 얻어지는 레이블이 어떤 형태인지 적어두었다.
데이터의 형태
입력(X)
- 길이와 F0 정보가 포함된 음소들 [(HH, 0.05s, 140 hz), (EH, 0.07s, 141 hz), … ]
레이블(Y)
- 주어진 텍스트에 대한 실제(ground-truth) 오디오 클립
이렇게 하여 우리는 파이프라인의 모든 부분을 학습시키고, 추론 과정을 성공적으로 해낼 수 있다.
요약
여기까지 온 것을 축하한다. 지금까지 Deep Voice가 어떻게 새로운 음성을 생성해내고, 어떻게 학습시켜야 하는지에 대해 보았다. 요약하자면, Deep Voice 학습은 아래의 단계를 따른다.
1. Grapheme-to-phoneme 모델
입력(X)
- “It was early spring”
레이블(Y)
- [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
2. Segmentation 모델
입력(X)
- “It was early spring”에 해당하는 음성 파일
- 음소들 [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
출력(Y)
- 음소쌍과 그 쌍의 음성 파일내의 시작시간 [(IH1, T, 0:00), (T, ., 0:01), (., W, 0:02), (W, AA1, 0:025), (NG, ., 0:035)]
3. Duration & F0 예측 모델
입력(X)
- 음소 [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
레이블(Y)
- [(IH, 0.05s, 140 hz), (T, 0.07s, 141 hz), … ]
4. 음성 합성 모델
입력(X)
- [(HH, 0.05s, 140 hz), (EH, 0.07s, 141 hz), … ]
레이블(Y)
- 주어진 텍스트에 해당하는 오디오 클립
이것이 전부이다. Baidu의 Deep Voice에 대한 포스팅들을 읽어주어 고맙다. 만약 어떠한 제안이나 개선점이 있다면 코멘트를 달아주었으면 한다.
번역 후기
이 글은 2017년 3월 10일에 작성되었던 글로, 벌써 2년이 지난 상태이다. 이 분야를 조금이라도 공부해본사람은 알겠지만 2년이면 엄청난 발전이 있기에 이 내용 또한 조금은 오래되었다고 볼 수 있겠다. 다만, 개인적으로 음성 분야는 이미지 처리와 다르게 조금 어렵게 다가오는 부분이 있었고, tacotron 까지 다가가는데 있어 조금은 기본적인 이해에 도움이 될지 싶어 한번 작성해보았다.
이번 음성관련된 포스팅은 직접 소스를 돌려보면서 진행하지 않아 머리속으로만 개념이 잡힌 것 같다. 한창 진행중인 일들이 마무리 되는대로, 실제 음성 데이터를 이용한 연구를 시작해면 아마 더 와닿는 것들이 있겠지 싶다.
그 때 또 이 포스팅에 덧붙여갈 내용이 있을 것이라고 생각해본다.
2 comments
반갑습니다 선생님, 좋은 글 잘 읽었습니다.
초면이지만 선생님과 몇 가지 연결고리가 생각나서 남겨봅니다.
1. 두경부암
지난 10년 저희 아버지께 발병한 4기 설암이 신촌암센터 이창걸 교수님의 토모테라피 치료로 기적처럼 완치되었습니다. 당시 저는 직장을 옮기고 적응하느라 정신이 없었는데 미국 어느 젊은 요리사 분의 설암 완치 자서전을 검색해보고 우리나라 미국 유명한 병원이라는 병원은 모두 연락하고, 제 인생과 관계 없었을 암에 대해 알아보고 그랬던 기억이 납니다. (올 해, 추가로 위암이 발견되었지만 수술 잘 받으시고 회복 중이십니다)
2. Deepfake Voice
마침 회사의 신사업 TF에서 Deepfake 관련 위변조 방지 솔루션을 구현하려고 노력하고 있습니다. 저는 사업 계획 담당이지만, 동료 개발자들의 대화를 들어보면 선생님이 올려주신 글에 나오는 표현들이 등장하더군요.
개인적으로는 AI기반 Deepfake와 이를 막는 (이라기보다 구분하는) 노력은 의학 또는 정보통신 방식의 표현을 빌자면 바이러스와 백신의 관게 처럼 지속해서 공격과 방어를 주고 받는 모습이 될 것이라고 생각합니다.
그럼 종종 뵙겠습니다. 감사합니다.
반갑습니다~여러모로 힘든 시기를 겪으셨겠네요, 아무쪼록 다 잘 해결된 듯 해서 다행입니다.
저는 비록 인공지능/딥러닝이 제 본업은 아니지만, 접점을 찾아보고자 이리저리 애쓰고 있습니다.
화이팅하세요~!