

(중간단계 결과물)
Source code : https://github.com/junn279/nodejs_python_communication
지난 포스팅 (https://steemit.com/kr/@junn/python-mediteam-us-tf-idf-konlpy 혹은 https://junn.net/archives/1923) 에 이은 진행과정 정리
이번 과제는 지난번에 만들었던 관련글 찾기에 이용하기 위해 nodeJS 와 Python간의 상호 호출에 대한 예제이다. 물론 실제적으로는 소스 코드 내부에 SQL 에 접속하여 자료를 가져오고, 분석된 토큰을 저장하는 과정은 생략해두었다.
사실 엄밀히 말하자면 이렇게 두개의 다른 언어로 제작할 필요가 전혀 없다. 파이썬 만으로도 사용해도 괜찮고, NodeJS에서는 konlpy 라이브러리를 쓰지 않고 mecab-ya (http://think.golbin.net/post/142517991186/%ED%95%9C%EA%B5%AD%EC%96%B4-%ED%98%95%ED%83%9C%EC%86%8C-%EB%B6%84%EC%84%9D%EA%B8%B0-for-nodejs) 라는 개발자분이 만드신 Token화 라이브러리를 써도 된다. 그러나 연습삼아, 그리고 이미 작업된 코드들이 있다보니 굳이 불편하게 이런 방식을 채택해보았다.
소스 코드의 구성은 다음과 같다.
1. tokenizer.js 에서 tokenizer_twitter.py 를 호출(call), argument 로 token화가 필요한 본문(Text)을 넘겨준다.
Python을 호출하는 nodeJS 라이브러는 python-shell 이다.
이때 본문에 있는 특수문자 혹은 띄어쓰기에 대한 대안으로 base64 를 이용해 encoding 한다.

2. tokenizer_twitter.py에서는 받은 argument를 디코딩 한 후 이전 포스팅에서 설명했던 Twitter 클래스를 이용해 명사(noun)만 추출한다.
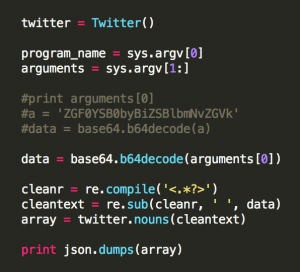
그리고 출력은 토큰화된 자료를 JSON 객체화 하여 출력하면,
3. 다시 tokenizer.js에서 이 출력된 글자를 받아 JSON object로 parsing해준다. (애초에 출력을 JSON 화 하여 출력하기 때문에 parsing시 에러가 발생하지 않는다) 참고로 이 출력은 pythonShell.run에 대한 리턴값이다.
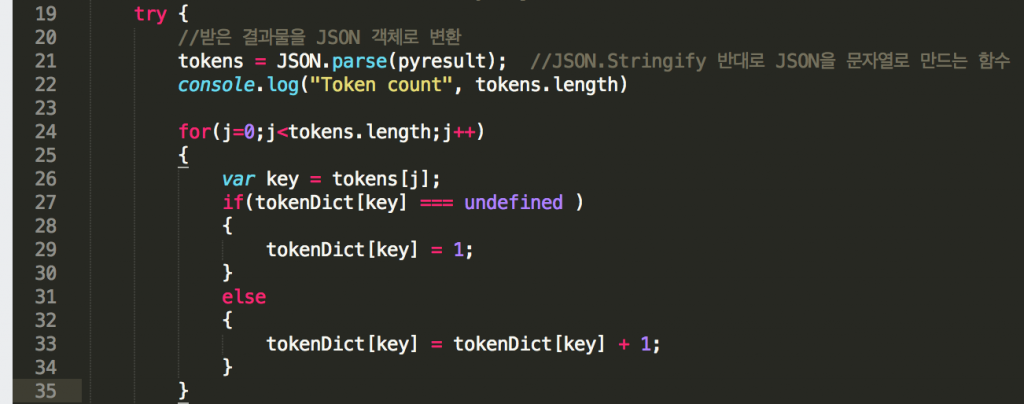
이러한 방식으로 값이 오가는데, 생각보다 python에서 konlpy 실행에 시간이 소요된다. 이 경우 비동기식으로 함수를 호출하면 중간에 자료 처리에 혼선이 올 수 있을 듯해서, synchronize 함수를 사용했다. (참고 : https://junn.net/archives/1038)
위의 소스는 사실 간략화 된 것이고, 여기에 mysql을 이용한 DB 입출력을 포함되면

지난번 포스팅과 같은 반복되는 명사 값을 계산하여 저장해 둘 수 있다.
안 해본 작업을 해보려니 생각보다 쉽지 않은 듯 하다.
다음에는 이제 위의 token 값들을 이용한 TF-IDF 값 계산을 통한 실제적인 ‘관련글 목록’을 만들어 내는 작업을 마무리하고자 한다.
2 comments