
이번 작업은 ‘관련있는 글 찾기’에 대한 테마로 진행하였다.
머신러닝과는 직접적인 관련이 없지만, Vector화에 대한 개념을 잡기위해서는 좋은 시작점일 듯 해서 시도해보았다.
내가 컴퓨터공학도가 아닌이상 알고리즘에 대해 깊숙하게 들어갈 필요는 없다고 보았고, 또한 word2vec, doc2vec 등의 이미 알려진 라이브러리를 바로 사용하기 전에 개념을 파악해보기 위한 목적 이었다.
역시 이 글을 남기는 것은 추후에 내가 다시 보기 위함이 크다.
아직 소스가 완전하지 않기 때문에 완성된 버전은, 이 시스템을 서버로 이식하는 과정과 함께 다음편에 github에 올려놓으려고 한다.
————-
관련글을 검색한다는 것은 즉 문서간의 유사도를 검색하는 방법이다. 가장 관련있는 글 5개라면 당연히 가장 유사한 글 5개를 찾는 것과 같은 이야기이다.
두 글의 유사성을 찾기 위한 알고리즘은 다양한 것 같았다, 검색해보니 가장 기초적인 작업이 TF-IDF 및 Cosine similarity라는 것이 있다.
TF: Term frequency – 한 문서에서 어떤 단어나 나온 횟수 / 전체 단어의 수
그 문서에서의 그 단어가 얼마나 중요한지에 대한 지표로 쓸 수 있다.
IDF: Inverse Document Frequency – Document frequency는 어떤 단어가 나온 문서의 수 / 총 문서의 수다. 이를 역으로 취해서 log를 씌워버리면 IDF가 된다.
그럼 어떤 문서의 벡터값은 TF * IDF로 구해지게 된다.
무슨이야기 인지 예를 들어보면 다음과 같다. (약간 과장된 예시다)
1. 나는 사과가 좋아한다.
2. 나는 배가 좋아한다.
3. 그는 컴퓨터가 좋아한다. 너무 좋아한다. 진짜 좋아한다.
4. 그는 사과를 좋아하지 않는다.
위 4개의 문장에서 ‘좋아한다’라는 단어는 모든 문장에 한번 등장한다. 따라서 어떤 문장에 좋아한다가 3번 등장한다 하더라도, 문서의 특성을 구분짓는 역할은 하지 못할 것이다.
따라서 ‘좋아한다’ 라는 단어가 나온 문장은 총 4개, 그러나 전체 문장은 4개이기 때문에 log값을 구하면 0이 나온다. 즉 TF값이 높아도 ‘좋아한다’라는 벡터 성분의 값은 0이 된다. => “문서의 특성을 구분짓지 못한다”
그래서 TF*IDF를 계산해주는 것이다.
문장 ‘벡터’는 예를 들면 아래와 같다.(예를 들자면)
문장1 {나:0.01},{그:0.0},{사과:0.01},{배:0.0},{컴퓨터:0.0},{좋아한다:0.0}
문장1에 등장하지 않았던 단어들도 일단 벡터를 구성하는 요소가 될 수 있다. (물론 코딩할때 꼭 들어갈 필요는 없다. 다만 numpy를 통해 행렬 계산을 용이하게 하기 위해선 필요할 수 있다)
이제 이렇게 백터를 구해놓은 여러개의 문서들을 서로 Cosine similarity를 통해 구한다.

벡터의 내적과 같다. TF-IDF를 통해 구한 벡터의 요소들은 모두 양수이기 때문에, 2차원으로 가정한다면 모두 1사분면에만 존재하는 값들이다. 따라서 90도 이상으로 벌어지지 않는 것이고, 90도라면 similarity는 0이 나오게 된다. 0도라면 1이 나올 것이고. 즉, 문서를 벡터화 시키고, 그 벡터들의 위치관계를 파악함으로써 유사성을 파악하게 된다.
이론을 말로 풀으려니 조금 복잡하다.
아무튼 그래서 나는 다음과 같은 라이브러리를 사용했다.
한글 문서 Tokenization : konlpy (http://konlpy-ko.readthedocs.io/ko/v0.4.3/) 의 Twitter Class 를 사용했고, 단어 중 명사(noun) 만 빼내었다. 그냥 모든 성분 분석을 그대로 사용해버리면 아래와 같은 단어들도 포함된다.
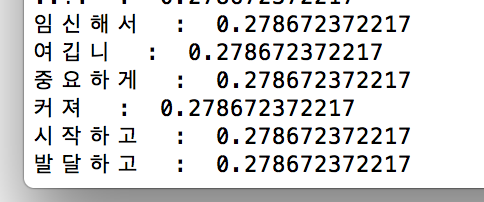
여깁니, 커져, 시작하고..이런 단어들은 사실 그냥 봐도 의미있는 것 같지가 않았다. 그래서 noun만 이용하기로 했고, 나름 괜찮은 결과가 나오는 것 같았다.
TF-IDF값이 높은 순서대로 정렬했더니, 아래의 글에서는 정맥->하지정맥류 등등의 순서로 나오는 것을 확인했다.
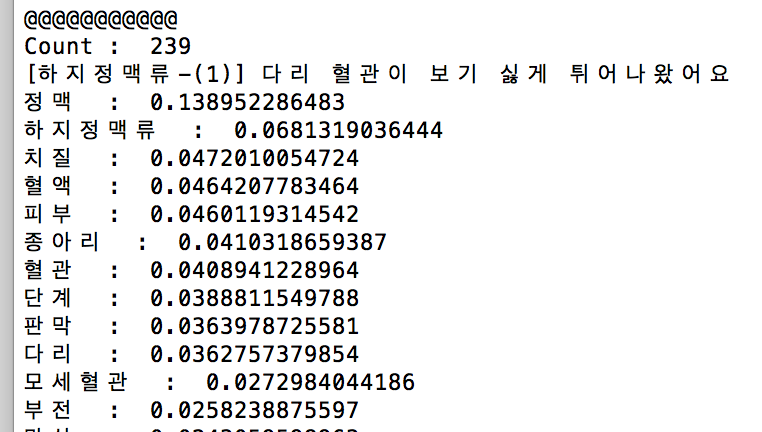
최종적으로 이렇게 구한 벡터값들로 240개의 글에 대한 유사성을 구하였고, 나름 만족할만한 결과를 얻을 수 있었다.
가장 유사한 3개의 글을 출력해보았다.

내가 썼던 글과 유사한 글로 첫 번째로 나온 것이 인공지능에 대한 이야기. 인공지능 글은 아직 두개뿐이라, 그 다음 결과들은 ‘검사’와 관련된 내용이라서 분류된 것이 아닐까 한다.

검진, 검사로 이루어진 주제들

암에 대한 이야기들

외과와 관련된 이야기.
나름 괜찮은 것 같다.
이제 이것을 서버로 이식해야하는데, 일단 konlpy가 작동되는데 시간이 오래 소요된다. 아마 자바를 끌어와서 사용하기 때문인듯.
1. Crawling할 때 받은 문서에 대한 단어별 TF-IDF를 구해놓는다.
2. Crawling할 때 받은 문서만 기존 Word Set를 이용해 유사한 문서를 찾아놓는다.
3. 하루에 한번 전체적으로 유사한 문서를 다시 구한다. (이미 TF-IDF값은 다 구해져 DB에 저장해 놓았기 때문)
References :
1. https://en.wikipedia.org/wiki/Tf%E2%80%93idf
2. http://secmem.tistory.com/670
3. http://think.golbin.net/post/142517991186
4. https://github.com/golbin/node-mecab-ya
5. http://arkainoh.blogspot.kr/2017/09/python.text.classification.html
6. https://ratsgo.github.io/natural%20language%20processing/2017/03/08/word2vec/
7. http://www.neuromancer.kr/t/word2vec/487
8. http://euriion.com/?p=548
9. http://euriion.com/?p=411929
10. https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/04/20/docsim/
6 comments
안녕하세요! 글 잘봤습니다.
명사로 추출한 후, 그것을 tf-idf로 어떻게 옮기셨는 지 알 수 있을까요?
지금 명사로 추출한 단어와 빈도수를 따로 텍스트 파일에 저장했습니다.
감사합니다~
안녕하세요. loop를 돌리면서 카운트 해서 구하시면 됩니다.
위키에서 참조한바에 따르면,
예를 들어 ‘A글에서 <사과>라는 단어에 대해 TF-IDF 값’을 구한다면,
전체 글의 수를: n
전체 글에서 ‘사과’라는 단어를 포함한 문서의 수: m
A라는 글에서 검색된 총 단어의 수: w
A라는 글에서 ‘사과’가 반복된 횟수: k
TF는 k/w 이 됩니다.
IDF는 log(n/m) 이 됩니다.
TF-IDF는 k/w * log(n/m)이 되겠습니다.
결국 위의 값을 구하시려면, 같은 단어라도 각각의 글마다 TF-IDF값은 다를 수 있기 때문에, DB를 이용하지 않는다면 저 값들을 세부적으로 저장해두기가 간단하지는 않을 것 같은 생각이 듭니다.
도움이 되셨는지 모르겠네요.